Parallel Hardware
As recently as fifteen years ago, parallelism was really only applicable to supercomputers and very large servers, but since then there has been a huge shift towards parallelism, and today almost every computer offers some sort of parallel hardware. However, getting the most out of this hardware can be challenging and in many cases still requires specialist programming techniques.
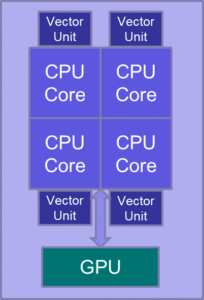
A typical modern PC or server (left) provides three distinct levels of parallelism:
• Multicore CPUs – modern CPUs contain several independent cores, each capable of performing a distinct task at the same time. Laptops, phones and tablets typically have 2-8 cores, while large servers and supercomputers may have 12 or more cores per CPU. Multicore CPUs can be exploited using APIs such as OpenMP or Pthreads.
• Vector units – each CPU core also has a vector unit attached. This allows the same calculation to be performed on multiple (typically 2-8) data items simultaneously. Ideally the vector units can be exploited automatically by the compiler, but to ensure optimal performance it can be necessary to hand-code using intrinsics (special functions that are mapped directly to specific machine instructions).
• Graphics Processing Units – GPUs were originally developed for rendering real time 3D graphics for games, but they can also be used for general purpose computation. They can be programmed using APIs such as CUDA or OpenCL.
High-performance computing (HPC) platforms such as supercomputers and compute clusters (right) take this approach one step further: while PCs feature a handful of processors connected through a common bus, HPC platforms include a large number of multi-core processors, connected with each other through very fast interconnecting networks. They are programmed using the Message Passing Interface (MPI), which allows processors to compute different areas of the code in parallel, while each utilising their own memory space. Some HPC platforms feature large, shared memory, and are typically programmed using OpenMP. Hybrid codes are also commonly encountered, with MPI distributing computation across multi-core processors and OpenMP used to further parallelise execution inside each processor. Some HPC platforms also host GPUs, opening up further avenues for parallelisation.
The different levels of parallelism tend to be effective for different sorts of codes. GPUs can give impressive speed-ups for codes that repeat the same simple calculation for a huge number of data items, but are not so effective when the volume of data is small or when the calculation is more complex. Multiple cores work well when there are several independent (or almost independent) tasks to be performed, for example a number of plates or strings to be simulated, and each one can be assigned its own core. For smaller problems, however, the overhead of synchronising the code running on each core can outweigh the advantage of using multiple cores. Vectorisation usually avoids this synchronisation overhead but can be less flexible and harder to program than multicore. High-performance computing gets called upon in NESS when we are dealing with a problem of very large scale, where the computation cannot conclude on multicore or GPU in realistic timescales.
It is also possible to use two or more forms of parallelism in the same code. For example, the Multiplate 3D code is very demanding and it was only by combining GPU acceleration, multicore parallelism and vectorisation that a good speed-up was achieved for this code.
Other Optimisations
Although most of the speed-ups gained on the NESS codes are due to parallelisation, various other optimisation techniques have also been used:
• Better data layouts – many of the codes make use of sparse matrices. In some cases significant performance improvements can be realised by using a data storage layout that takes their structure into account (for example, a special format for diagonal banded matrices) rather than using a generic format such as Compressed Sparse Row (CSR).
• Reducing memory accesses – memory access often tends to be a bottleneck on modern computers, so sometimes it is faster to calculate a value on-the-fly instead of reading it from memory. In some codes the memory bottleneck can also be helped by merging calculations together so that the intermediate results don’t need to be written back to memory in between.
• Rank reduction – linear system solve operations are among the hardest to accelerate as they generally require a series of sequential steps that can’t easily be parallelised. However, in some cases only a small number of elements in the system are actually dependent on each other, so it is possible to reduce the solve to a smaller operation that runs much faster.
• Mixed precision – although most of the NESS codes have to be run in double precision floating point for numerical stability reasons, it is sometimes possible to run parts of them in single precision. This allows the data to be processed twice as fast in these parts of the codes.
• Alternative algorithms – sometimes a more efficient algorithm can be substituted for a less efficient one. For example, one code was sped up by more than 100x by restructuring the code slightly and replacing a linear search operation by a binary search.
Applying the techniques
This table shows which techniques were used to speed up each of the NESS codes, as well as how much faster the final version is compared to the original Matlab version, and roughly how long it takes to run a one second simulation:
| Code |
Techniques Used |
Speed-up over Matlab |
Typical time for 1s simulation |
| Zero Code |
GPU |
25x |
28s |
| Multiplate 3D |
GPU, multicore, vectorisation, banded matrices, merging of operations, mixed precision |
60x |
4m |
| Brass |
Vectorisation, memory bandwidth reduction |
15x |
0.9s |
| Guitar |
Multicore, rank reduction |
21x |
4.5s |
| Modal Plate |
Multicore, vectorisation |
12x |
1.75s |
| Net1 Code |
Multicore, rank reduction |
60x |
0.75s |
| Bowed String |
Multicore, algorithmic changes |
220x |
0.5s |
The 3D room codes have been ported to GPU and also parallelised on the UK’s National HPC Service Archer. Because of the varied size of rooms, there is no typical scenario to demonstrate speed-up. It is however the case that, in general, GPU-accelerated 3D-rooms run faster than the HPC solution, although the latter can scale to accommodate much bigger rooms.
In the remainder of this page we discuss the acceleration of the Multiplate 3D code and the HPC implementation of the 3D rooms.
Multiplate 3D Code

It is worth considering the Multiplate 3D code in more detail as it is an interesting case where a combination of several different optimisation techniques was required in order to gain acceptable performance. The model itself was one of the most complex ones developed on the NESS project. It simulates a number of metal plates embedded within a three dimensional box of air. The plates are modelled using non-linear equations as this gives a more realistic sound output, especially when they are struck hard. The interaction between the plates and the surrounding air also has to be simulated, so that when one plate vibrates, the sound waves propagate through the air and cause a slight movement of the other plates as well. With relatively minor changes to add support for circular membranes and a drum shell, the same code can also simulate a bass drum.
The combination of the complex non-linear plate model with the 3D air model, as well as the interface between them, made this a uniquely difficult code to accelerate. In isolation, the air box would be a good candidate for GPU acceleration, but the linear system solve operation required to update the plates made it unrealistic to simulate them on the GPU, and initially there were concerns that splitting the model between CPU and GPU would result in an unacceptable loss of performance due to the time taken to transfer data over the relatively slow PCI bus between them.
The eventual solution involved exploiting parallelism at three distinct levels, as well as other changes. The most important optimisations are summarised below:
• The biggest bottleneck, the preconditioner for the linear system solve (required every simulation time-step for each plate), was vectorised using SSE (Streaming SIMD Extensions) instructions. It was also converted to single precision as testing showed that this did not compromise the stability of the code.
• The operations used to build the system matrix for the solver were also extensively optimised. Generic Compressed Sparse Row matrix storage was replaced by more efficient diagonal banded storage, and some operations were combined to avoid writing data back to memory in between.
• Each plate was assigned to a separate core of the CPU, allowing them all to be updated at the same time.
• The air box was updated on the GPU at the same time as the plates on the CPU. The points immediately adjacent to the plates cannot be included in this as they depend on results from the plate update, but they account for a very small proportion of the total and can be updated separately at the end without impacting performance too much. Because the interpolation between plate and air grids is also done on the GPU, the amount of data needing to be transferred across the slow PCI bus is minimised.
Overall, the optimised code is around 60-80 times faster than the original Matlab, depending on the problem being simulated. This work is discussed in more detail in a conference paper presented at ParCo 2015.
3D room acoustics simulation
Part of the NESS work has been to look at modelling the acoustics of three dimensional spaces. There are numerous methods to do this, such as ray tracing, but many of these methods have some sort of compromise or approximation in their approach, and as such have associated artefacts and fidelity issues. What NESS proposed was to solve the 3D-wave equation directly over a representative grid, using the Finite Difference Time Domain (FDTD) approach. Historically this approach was considered too computationally expensive to be used at any practical scale, but over recent years it has become a more realistic proposition, specifically via a GPU or High Performance Computing (HPC) approach.

At its simplest, the FDTD method involves representing a room by a 3D grid of equally spaced points, and then solving the 3D wave equation for this grid in a sequence of time-steps, as shown on the figure. The FDTD stencil update employed in NESS relies on the neighbouring grid points from the previous two time-steps – thus the state of the model requires 3x storage of a single grid, adding to the memory requirements. The main challenge in this approach is managing the size of the grid and the number of calculations required to get a reasonable length of output sound. Both the grid spacing and the time-step gap are defined by the sample rate of the acoustics being investigated – a higher sample rate generates better quality output, but implies a finer grid and a shorter step. A doubling of sample rate incurs an eightfold increase in grid points (double grid points per dimension, three dimensions) and a halving of the time-step, thus sixteen times more computations required per second of output, and eight times more storage. Thus, the FDTD method can quickly become a very computationally and memory intensive approach, enforcing the use of advanced computing power.
Initially the NESS team developed a GPU version of the 3D room code. The GPUs are well-suited to the computational demands of the algorithm and provided good performance, however they can only take us so far due to the limited memory of the GPU. For example, a room model representing a cube of 16-meter per side, sampled at a rate of 44.1kHz, requires in the order of 1.6×109 grid points, about 28GB – a typical GPU has 8GB. There are ways around this, for example some machine architectures allow multiple GPUs to be used in parallel, however, these machines are quite rare. NESS considered a different approach – using the Message Passing Interface (MPI) to write a version of the code which could be run on any parallel machine. For example, the UK national HPC service machine ARCHER hosted by EPCC is a Cray supercomputer with over 100,000 processing cores and in excess of 300TB RAM – an MPI code in theory could make use of the whole machine, thus memory issues cease to be a problem, and we can consider running models at both higher sample rates and larger dimensions. The MPI paradigm launches multiple copies of a standalone executable, each with its own memory space, and any communications between these instances of the executable is done using MPI calls from within the executable.

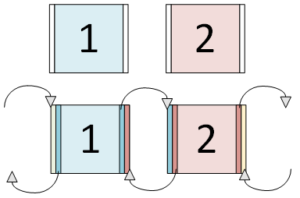
The basis of our HPC implementation is to parallelise the simulation by splitting the model grid to run over several processors, with each processor performing calculations only on its own partition of the room, as seen in the figure on the left. Our room model is partitioned over the available processors, in this case, 8. Each process operates on its own section of the grid points.
However, our stencil update requires input from each neighbouring grid point – in our parallel implementation, the neighbouring grid point may be on a separate process, and thus be inaccessible. This is where MPI comes in – it allows us to communicate between individual processes. Each process calculates its own edges, then sends them via MPI to its neighbours, who can then store those values in extra memory space and use them in the next time-step. The figure on the right illustrates this mechanism. Each process has an additional “halo” of storage space so it can store an extra slice of data from its neighbouring processors. At each time-step this edge data is sent between processors, ready for use in the next time-step.
Parallelising in this way allows us to run much larger problems than previously possible, however, they still take a long time for run – for our 16-metre per side cube discussed earlier, running on 240 processor-cores, it takes of the order of 80 minutes of wall clock time to produce one second of audio output. Thus we often have to run the code for a long time to get usable output, but for a longer runtime there is a higher risk of losing computation e.g. due to machine failure. In order to counter this, we have implemented check-pointing – this incurs little computational overhead and allows the state of the system to be stored at any given point, which can then be used to restart the simulation from that point at some time in the future, meaning calculations up to that point have not been wasted.
So far, we have used the MPI 3D code in several ways to model sources in a room. Firstly, we generated an acoustic response for the room for a static source, which can then be used again multiple times with some post-processing to see what various input sources sound like in a given space. Then we looked at moving sources: initially, these were just a source moving at a constant speed in one direction, but we have since implemented a breakpoint function which allows arbitrary movement and speed to be simulated. The rooms were initially rectangular, but we have now implemented code to support L-shape rooms, allowing us to “hear” movement around a corner. For each of these different approaches we can put multiple listening points throughout the room, as these impact relatively lightly on the computation.
Some examples of the outputs we have simulated follow below. Please note that these are either mono or stereo WAV files so full “surround” motion effects will not be heard – we usually generate multi-channel outputs from the simulations (e.g. eight or sixteen-way) for playback in a studio.
Example 1: Trumpet in 16mx16mx16m cube room @ 44.1kHz. For this example we have an impulse response generated for the room, which is then convolved with a trumpet input to give the effect of the trumpet being in the room.
Dry trumpet input:
Trumpet in the room:
Example 2: Castanets in 13mx11mx8m room. Again this uses an impulse response, but we have two different sample rates to show how the artefacts change.
Dry castanet input:
Castanet in the room (44kHz):
Castanet in the room (88kHz):
Example 3: Siren in a 256mx4mx4m room. This moving source example demonstrates the Doppler effect as a siren travels at a constant speed through a long “tunnel”.
Indicative movie of source moving along tunnel
Dry siren input:
Siren in the tunnel:
Example 4: Motorbike in a 256mx4mx4m room @ 64kHz. In this example we use the motion breakpoint function – the motorbike is static as it is revving, and then accelerates through the tunnel. There are two simulations here: one with absorptive walls and one with rigid tunnel walls (so, more echoes).
Dry motorbike input:
Bike in anechoic tunnel:
Bike in tunnel:
Example 5: Mosquito in a 25mx25mx5m room @ 44.1kHz. In this example the mosquito follows a polar orbit around the centre of the room.
Indicative movie of mosquito motion.
Dry mosquito input:
Mosquito orbiting room: